
Marketing Cloud Personalization
Cross-Channel Personalization
Personalize every customer experience with AI and real-time data to optimize conversions and reduce costs.


What can you do with Marketing Cloud Personalization?
Treat every customer as an individual and drive ROI across your marketing programs with our personalization engine.
Personalize moments across the customer journey.
Create personalized experiences with machine learning and AI. Customize everything, from webpages to in-app experiences, product recommendations, content, and more. Tailor each customer experience for driving a specific KPI, from acquisition to customer retention, using a mixture of real-time user behavior and historical customer data. Improve page personalization with machine learning, informing CTAs like banners or pop-ups. You can even target and test at the speed your customers are browsing, with personalization decisions happening in milliseconds.
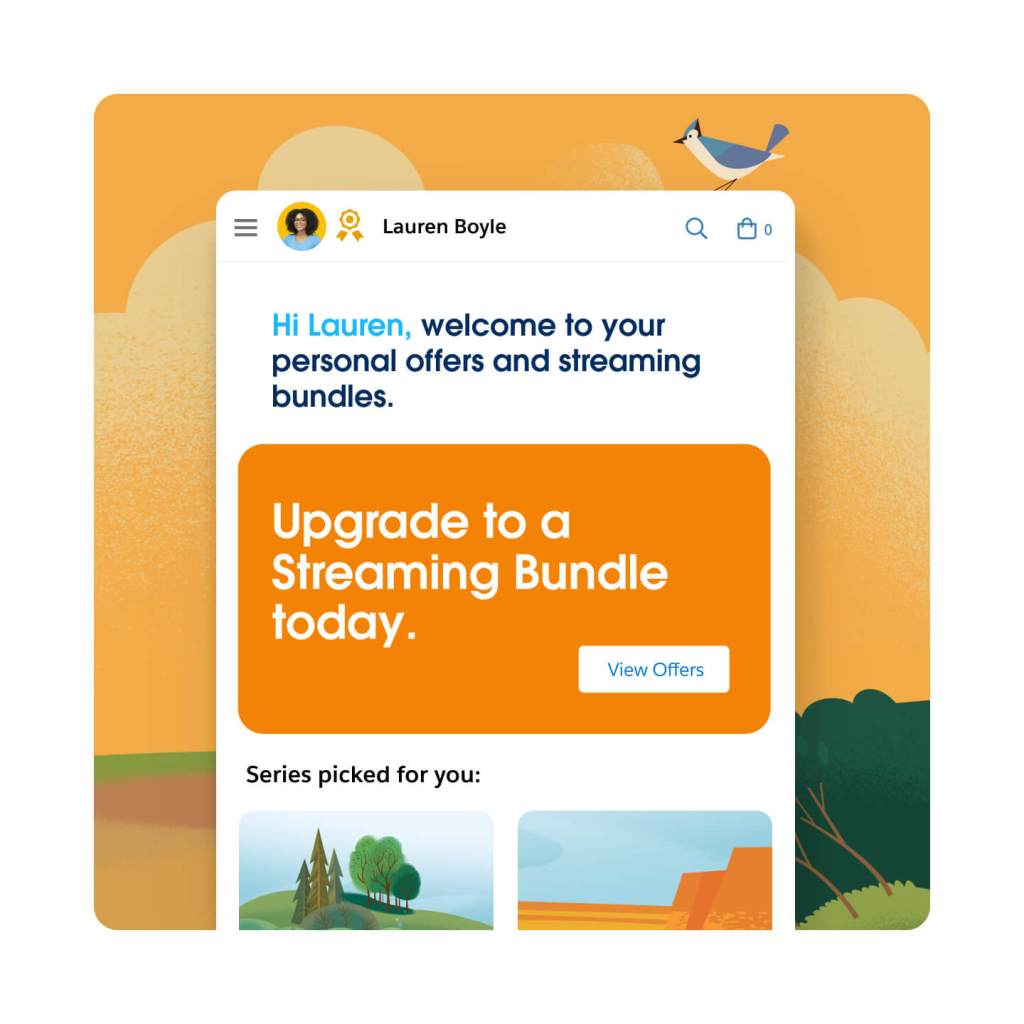
Trigger relevant, real-time experiences that move customers along their buying journey. Use AI-driven decisions to determine the most relevant next engagement for your customers with recommendations based on real-time customer behavior, historical customer data, and business specific data sets, such as pricing and inventory. Deliver predefined experiences to your customers, such as browsing or cart abandon journeys — all while using real-time customer interactions to determine the right content, channel or offer for them.

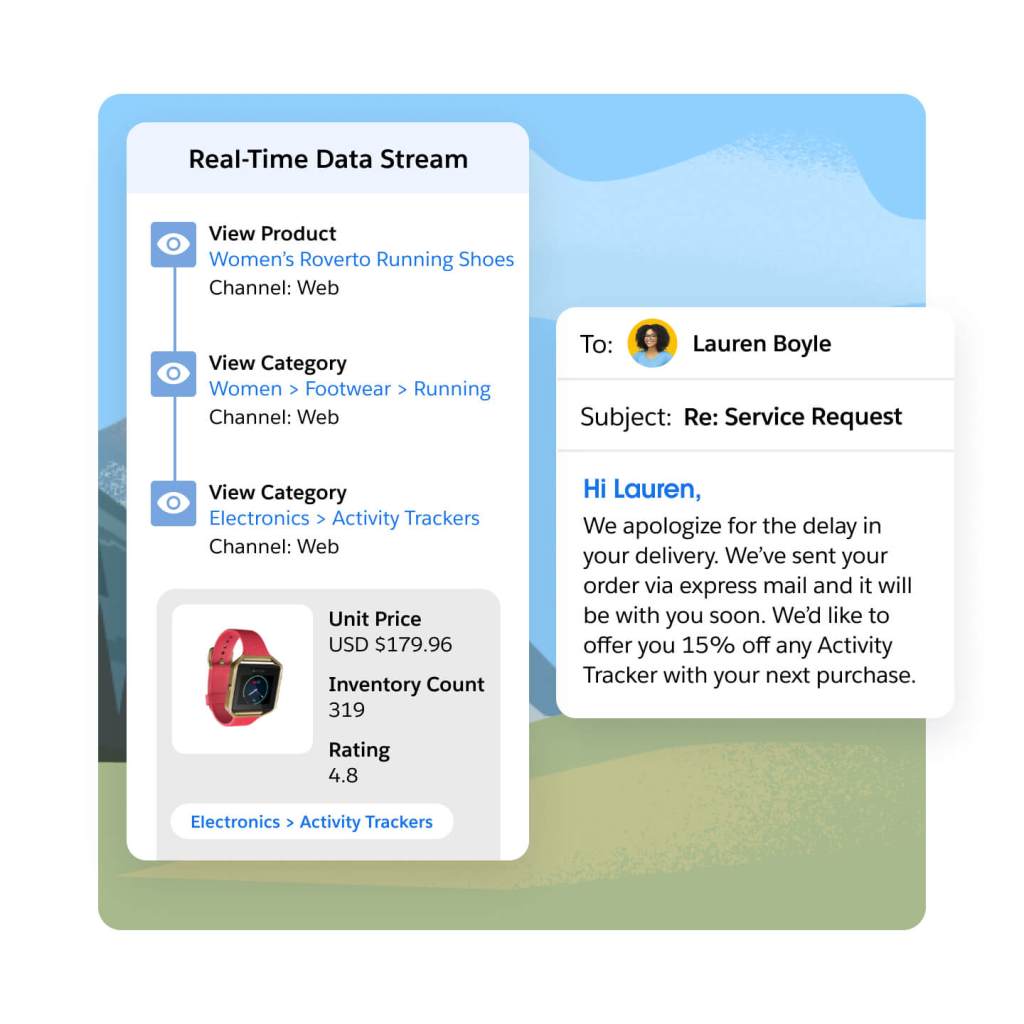
Feed real-time engagement data directly into your sales and service consoles to improve customer and prospect interactions. Empower service teams to preempt queries and provide more effective case resolutions, with faster access to a customer’s recent interactions across different business touchpoints. Enable your sales teams with more insight into an account or prospect’s purchase journey — fueling more relevant conversations and offers, using real-time knowledge of content consumed, products viewed, or time spent on your site.
Engage with real-time recommendations.
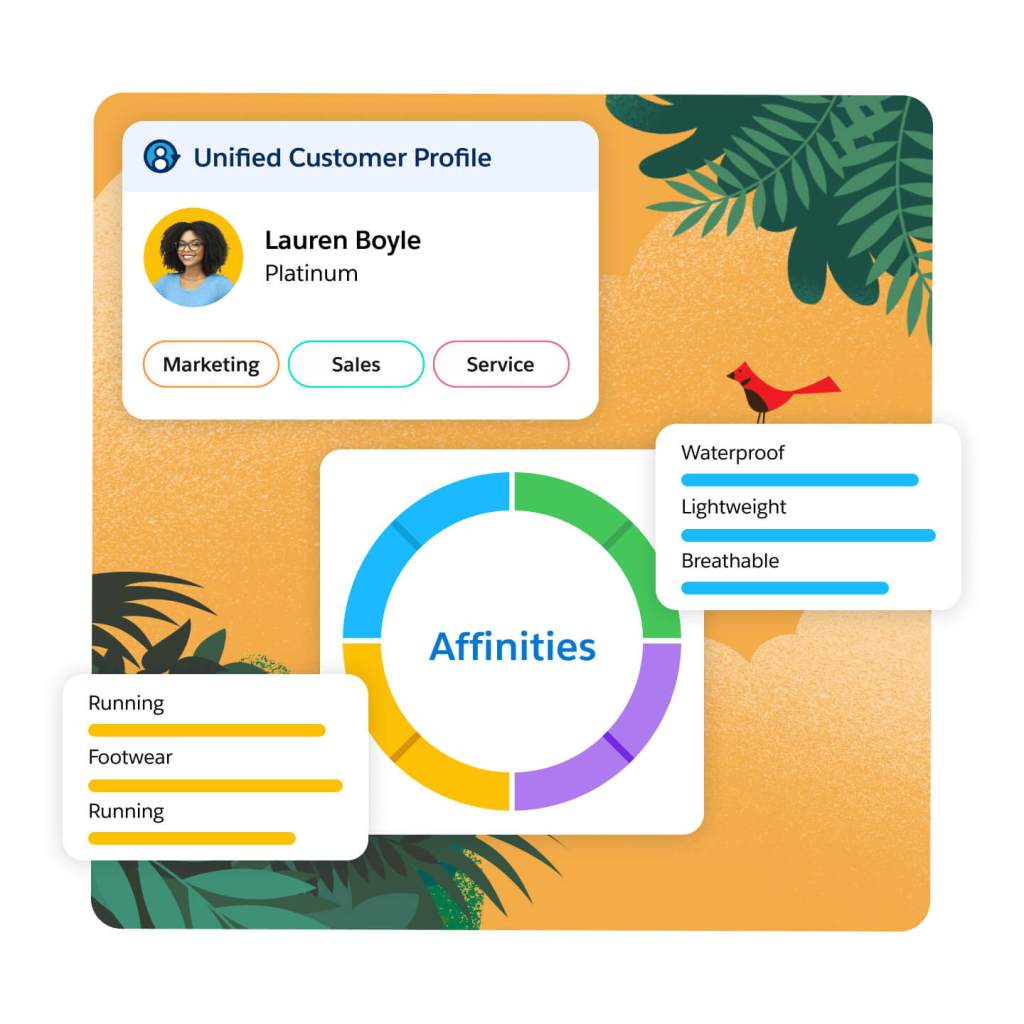
Use AI to synthesize in-the-moment intent data and past business engagements to identify customer affinities, interests, and preferences. Grow your personalization capabilities with a fully customizable affinity graph — allowing you to map and visualize rich, real-time customer profiles. Develop nuanced perspectives on your customers based on individual preferences and use these insights to deliver custom messaging and offers — bringing you higher conversion rates across your website, app, and other channels.
Use real-time personalization to engage your customers with relevant email campaigns. Send timely, custom messages with Open-Time Email Personalization that can optimize an email at the time of open with dynamic, changeable sections. Any aspect of the email can be personalized — including offers, product selection, and general content — all based entirely on the real-time understanding of the customer’s journey.

Improve the relevance of every customer engagement across your website and app with Einstein Decisions. Einstein Decisions are powered by a contextual bandit algorithm that uses real-time and historical profile data, alongside your predetermined business logic, to identify relevant, dynamic offers throughout the customer journey. As you deliver content and offers to your customers, new data will continually feed into Einstein — allowing the algorithm to improve its ability to deliver more optimal future decisions across a range of dynamic scenarios.

Maximize return on marketing campaigns.
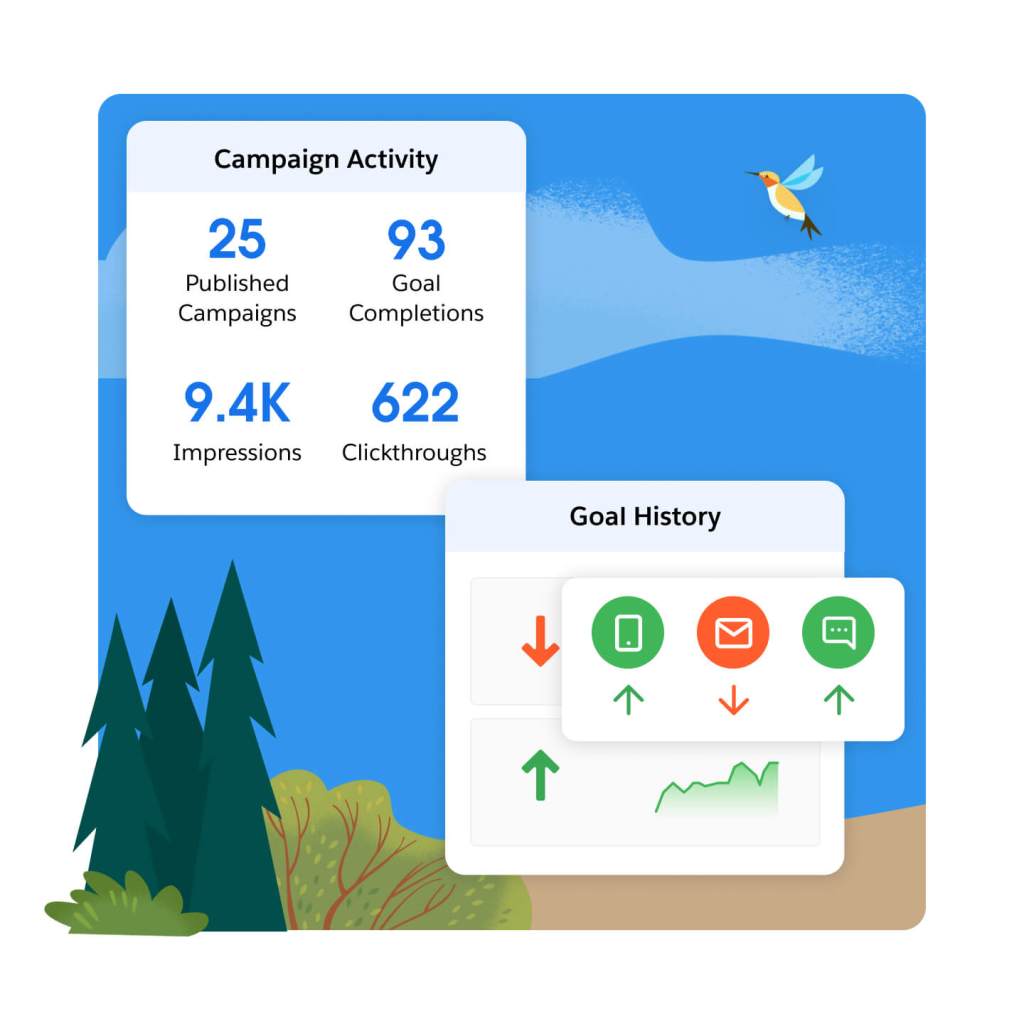
See real-time analytics across a range of key performance indicators — including transactions, responses, conversions, and revenue. Dig into your data at the individual, segment, and campaign level. Monitor dashboards with deep analytics on customer trends across channels and touchpoints, and improve your website and app experiences.
Optimize your web and app experience with A/B and multivariate testing. Leverage real-time, behavioral, contextual, and historical data to target tests, based on either segment membership or rule-based test triggers. Act on results with confidence, using randomized tests that employ Bayesian modeling to assess confidence levels for both out-of-the-box and custom KPIs. Integrate data to optimize personalization across channels — including your website, mobile app, email or service, and sales interactions.
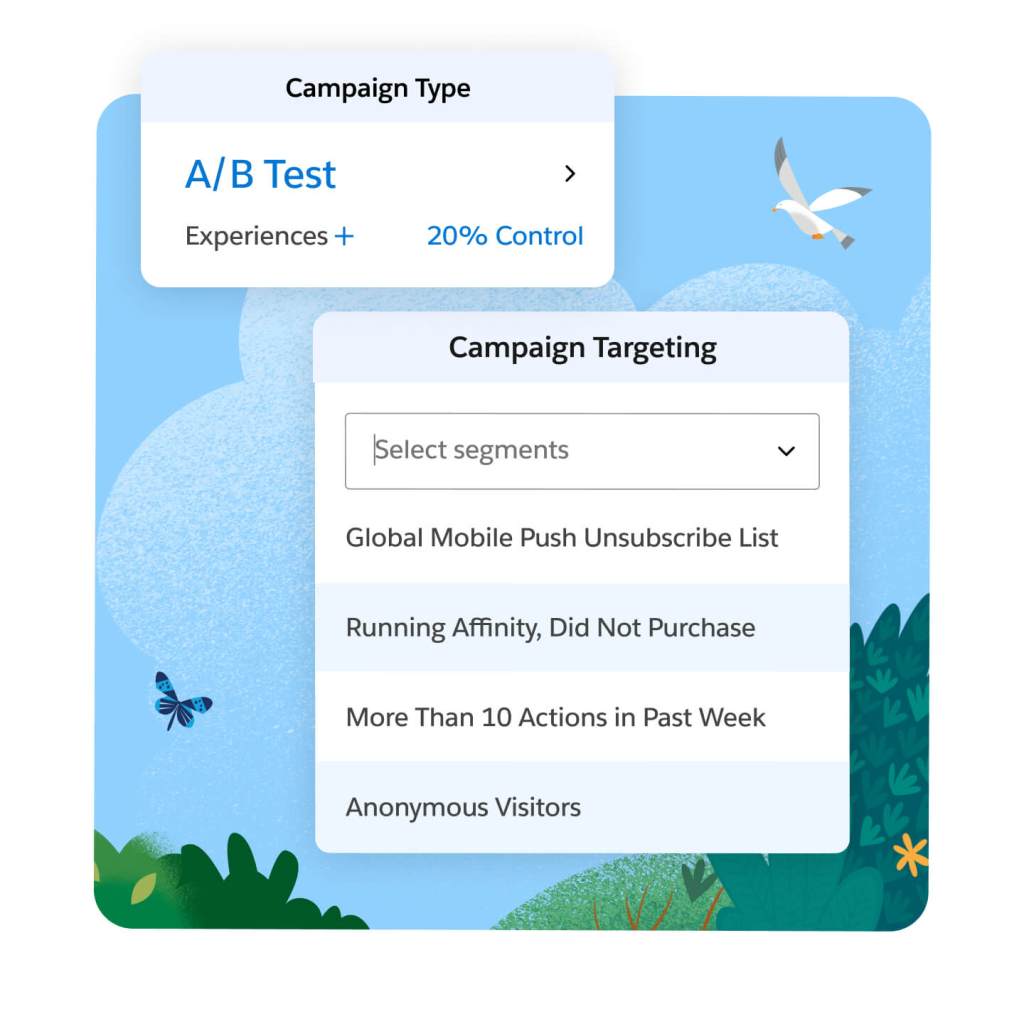
Use profile data to deliver highly targeted surveys across your website and apps. Capture zero-party data that enriches your customer insights and personalization opportunities through progressive profiling. Leverage individual responses to inform the next piece of content your customer receives and improve the effectiveness of different CTAs across your website and apps.

Extend the power of Marketing Cloud Personalization with these related products.
Data Cloud for Marketing
Activate your data, scale insights with AI, and unify all your data into a single customer profile.
Marketing Cloud Engagement
Create and deliver boundless, personalized customer journeys across marketing, advertising, commerce, and service.
Marketing Cloud Account Engagement
Grow efficiently by aligning marketing and sales on the #1 CRM with marketing automation and account-based marketing.
Marketing Cloud Intelligence
Optimize marketing performance and spend across every campaign, channel, and journey.
First, choose the right Marketing Cloud Personalization edition for your business needs.
Enable personalized content and offers across every channel.
Growth
Personalize every interaction across channels like your website and email
$
108,000
Org / Year
USD (billed annually)
- Web and Email Personalization
- Segmentation, Rule Based Decisioning, A/B/N Testing and Reporting
- Product and Content Recommendations
Premium
Supercharge cross-channel personalization with AI driven, next-best actions in real-time
$
300,000
Org / Year
USD (billed annually)
- Web, Email and App Personalization
- Segmentation, Rule Based Decisioning, A/B/N Testing and Reporting
- Product and Content Recommendations and AI-Driven Next-Best Actions and Offers
This page is provided for information purposes only and subject to change. Contact a sales representative for detailed pricing information.
Get the most out of your personalization engine with partner apps and experts.






Stay up to date on all things marketing.
Sign up for our monthly marketing newsletter to get the latest research, industry insights, and product news delivered straight to your inbox.
Learn new skills with free, guided learning on Trailhead.

Hit the ground running with marketing tips, tricks, and best practices.


Ready to take the next step?
Talk to an expert.
Tell us a bit more so the right person can reach out faster.
Stay up to date.
Get the latest research, industry insights, and product news delivered straight to your inbox.

Marketing Cloud Personalization FAQ
A personalization engine is a kind of technology solution that ingests customer engagement and profile data, then — using machine learning and AI — determines relevant messages, segmentation, and content for each customer, based on their preferences and affinities. These insights can then be ingested into various marketing touchpoints to power the customer experience.
Increase the ROI of every site visit with 1-to-1 personalization.
Many Marketing Cloud products offer the ability to personalize customer engagements, however, “Personalization” in Marketing Cloud refers specifically to the product that allows you to unify customer engagements across your website, app, email and other touchpoints, to generate preferences and affinities that power real-time one-to-one offers, messages, and experiences.
- Improved CSAT and customer experience
- Increased conversions on your website and across your email marketing
- Improved website and app experience, including increased time spent on-site and reduced bounce rate
- Reduced overall acquisition costs
- Improved marketing performance from smarter marketing segmentation
- Real-time triggers and intent driving engagements
Yes, Marketing Cloud Personalization and Salesforce Interaction Studio are one and the same. Interaction Studio was rebranded as Marketing Cloud Personalization in 2022.
Yes, Marketing Cloud Personalization and Evergage are one and the same. From increased innovations, feature improvements, and the evolution of the product, the name evolved twice from Evergage, to Interaction Studio, and then from Interaction Studio to Marketing Cloud Personalization.